I continue my publications on analytics:
- A Data Analysis in business - BI system and visualisation
- Analyses of Product Metrics
- А/B-tests - Part 1/3(AA-test)
- А/B-tests - Part 2/3(AB-test)
- A/B-tests - Part 3/3 (relationship metrics)
Airflow is a library that allows you to work with the schedule and monitoring of tasks performed, similar to GitLab CI/CD. This tool is designed to solve ETL problems (Extract->Transform->Load). The Airflow interface looks like this:
DAG is the main unit of work with Airflow. DAG stands for Directed Acyclic Graph. A graph is a set of points (vertices, nodes) that are connected by a set of lines (edges, arcs).
A directed graph, also called a digraph, is a graph in which the edges have a direction.
Graphs are called acyclic when in some directed graphs the development of the process can develop in a strictly defined direction - it is impossible to return back to the same element if you have already left it.
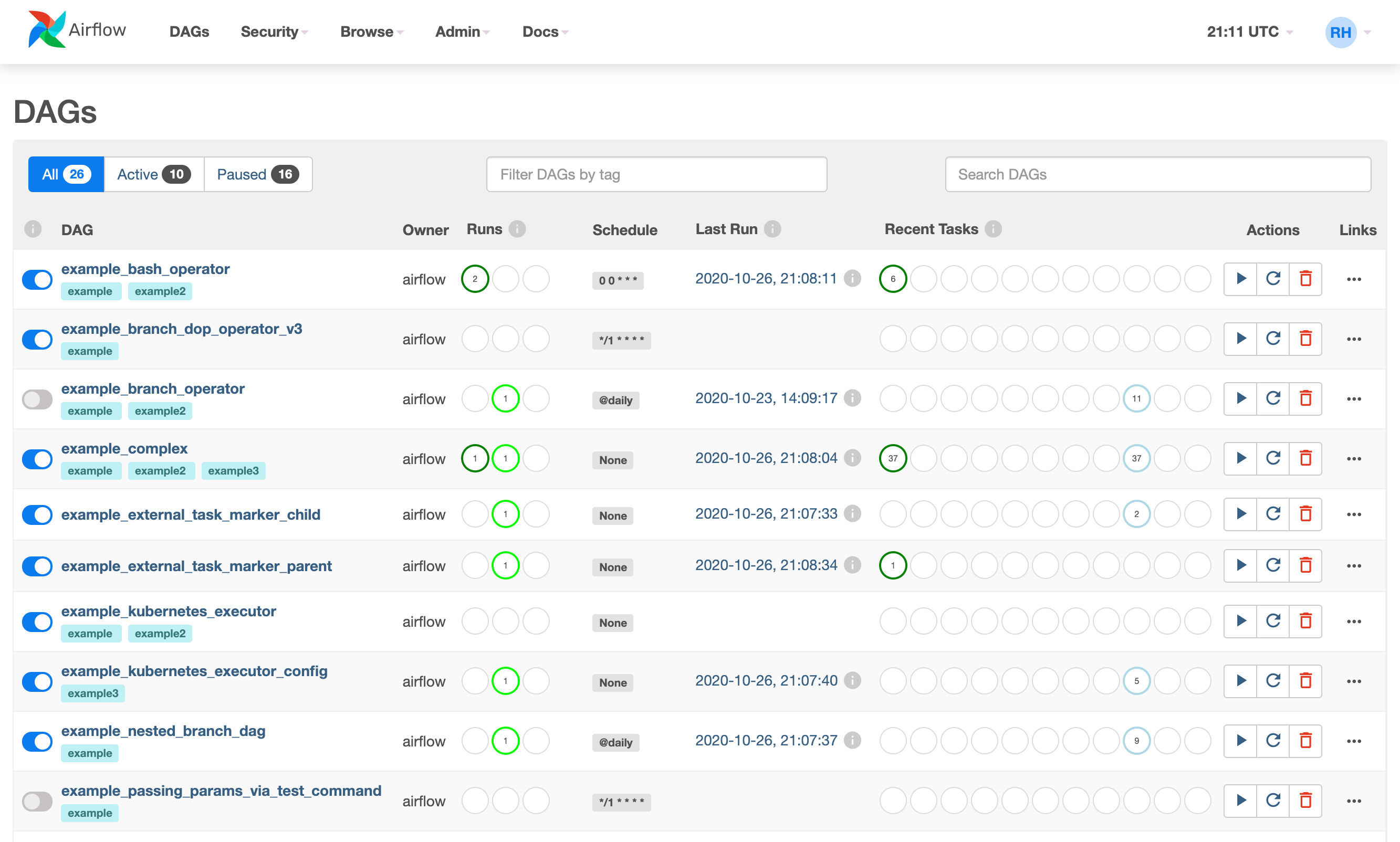
Let’s go back to Airflow. The main page lists all available DAGs and, the All, Active and Paused tabs allow you to filter DAGs according to their execution status. Each DAG has a switch that is responsible for whether the DAG is active or not, then comes the name, owner, information about launches and their states, schedule (in Cron format), information on the last completed tasks and some hotkeys for working with the DAG: launch instantly, restart and delete. If you open a specific DAG, you can see more information about it:If you open a specific DAG, you can see more information about it:

Here you can visualize the DAG, look at its schedule, the duration of the execution of “small” tasks, the number of DAG launches, as well as other interesting things. The “tree” display of the DAG is convenient because you can track the history of tasks in the DAG:
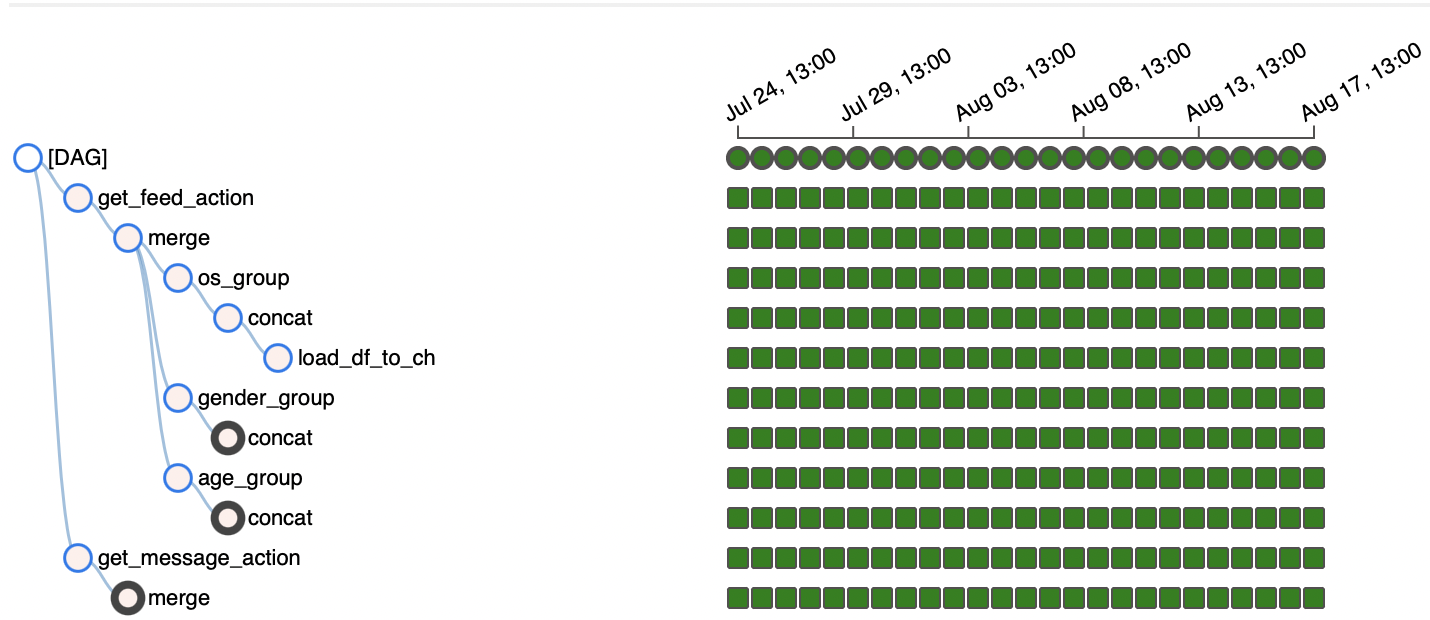
If something is broken (the task is highlighted not in green, but in some other color), you can click on it and open logs in the selected menu. This will allow you to track down what caused the breakdown.
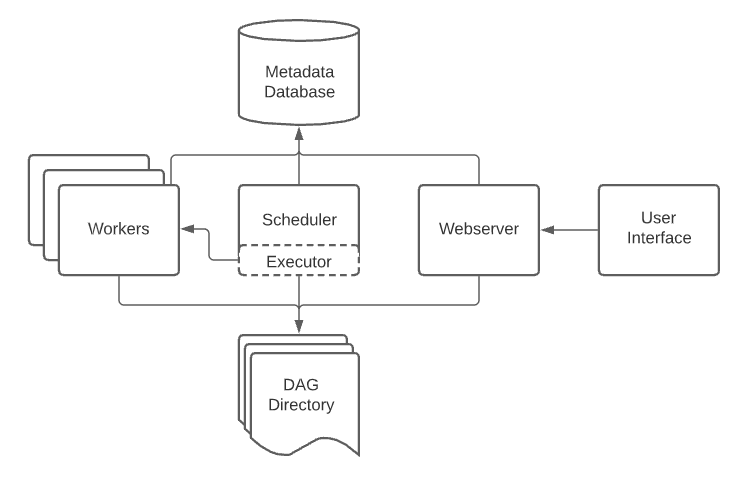
An Airflow installation generally consists of the following components:
- A scheduler, which handles both triggering scheduled workflows, and submitting Tasks to the executor to run.
- An executor, which handles running tasks. In the default Airflow installation, this runs everything inside the scheduler, but most production-suitable executors actually push task execution out to workers.
- A webserver, which presents a handy user interface to inspect, trigger and debug the behaviour of DAGs and tasks.
- A folder of DAG files, read by the scheduler and executor (and any workers the executor has)
- A metadata database, used by the scheduler, executor and webserver to store state.
The Task flow API is an add - on that first appeared in AirFlow version 2.0, greatly simplifying the process of writing DAGs. The main elements that we can now work with are decorators. Now, when we define our function in Python, we can mark it with the decorators @dag() and @task() - this way we let the interpreter know that it is working with a DAG or task. In order to use the Task Flow API, you must also import the corresponding functions.
from airflow.decorators import dag, task
To create a DAG, now it is enough to create a function inside which there are other task functions, and write the appropriate decorator @dag in front of it. An example might look like this:
default_args = {
'owner': 'a.gladkikh8',
'depends_on_past': False,
'retries': 2,
'retry_delay': timedelta(minutes=5),
'start_date': datetime(2022, 3, 10),
}
# DAG start interval
schedule_interval = '0 23 * * *'
@dag(default_args=default_args, schedule_interval=schedule_interval, catchup=False)
def top_10_airflow_2():
pass
We can also pass default_args arguments to the @dag decorator. These arguments define the behavior of our DAGs. You can also set others, including schedule_interval, which sets the frequency and time of the process. To create a task, add a new function to the -DAG function, which we mark with the decorator @task(). Parameters can also be passed to the @task() decorator. For example, retries indicates the number of repetitions of the DAG, if for some reason it did not work, and retry_delay indicates the time interval between these repetitions:
@dag(
schedule_interval=None,
start_date=pendulum.datetime(2021, 1, 1, tz="UTC"),
catchup=False,
tags=['example'],
)
def example_dag_decorator(email: str = 'example@example.com'):
"""
DAG to send server IP to email.
:param email: Email to send IP to. Defaults to example@example.com.
"""
get_ip = GetRequestOperator(task_id='get_ip', url="http://httpbin.org/get")
@task(multiple_outputs=True)
def prepare_email(raw_json: Dict[str, Any]) -> Dict[str, str]:
external_ip = raw_json['origin']
return {
'subject': f'Server connected from {external_ip}',
'body': f'Seems like today your server executing Airflow is connected from IP {external_ip}<br>',
}
email_info = prepare_email(get_ip.output)
EmailOperator(
task_id='send_email', to=email, subject=email_info['subject'], html_content=email_info['body']
)
dag = example_dag_decorator()
Separately, I want to make a digression on the decryption of the parameters passed during DAG initialization:
default_args = {
'owner': 'your_name', # Owner of the operation
'depends_on_past': False, # Dependence on past launches
'retries': 1, # Number of attempts to perform DAG
'retry_delay': timedelta(minutes=5), # The interval between restarts
'email': '', # Email for notifications
'email_on_failure': '', # Mail for error notifications
'email_on_retry': '', # Mail for restart notifications
'retry_exponential_backoff': '', # To establish exponential time between restarts
'max_retry_delay': '', # Maximum amount of time to restart
'start_date': '', # Дата начала выполнения DAG
'end_date': '', # Date of completion of DAG execution
'on_failure_callback': '', # Run the function if the DAG has fallen
'on_success_callback': '', # Run the function if the DAG is executed
'on_retry_callback': '', # Run the function if the DAG has gone to restart
'on_execute_callback': '', # Run the function if the DAG has started executing
# Задать документацию
'doc': '',
'doc_md': '',
'doc_rst': '',
'doc_json': '',
'doc_yaml': ''
}
schedule_interval = '0 12 * * *' # cron expression, you can also use '@daily', '@weekly', and timedelta
dag = DAG('DAG_name'
At the end, I will present my DAG hosted in airflow, which transmits data for the previous days. DAG logic:
- Processes two tables in parallel. In feed_actions, the number of views and likes of content is calculated for each user. In message_actions, for each user, it counts how many messages he receives and sends, how many people he writes to, how many people write to him. Each unloading is in a separate task.
- From the resulting table, it counts all metrics by gender, age and OS. Makes three different cars for each slice.
- Writes the final data with all metrics to a separate table in ClickHouse.
- Every day the table is updated with new data.
import pandas as pd
import pandahouse as ph
from airflow import DAG
from airflow.operators.python_operator import PythonOperator # Так как мы пишет такси в питоне
from datetime import datetime, timedelta
from airflow.decorators import dag, task
from airflow.operators.python import get_current_context
default_args = {
'owner': 'a-gladkikh-8',
'depends_on_past': False,
'retries': 2,
'retry_delay': timedelta(minutes=5),
'start_date': datetime (2022, 6, 10)
}
schedule_interval = '0 12 * * *'
connection_rw = {
'host': 'https://clickhouse.lab.karpov.courses',
'password': '656e2b0c9c',
'user': 'student-rw',
'database': 'test'}
connection_ro = {
'host': 'https://clickhouse.lab.karpov.courses',
'password': 'dpo_python_2020',
'user': 'student',
'database': 'simulator'}
@dag(default_args=default_args, schedule_interval=schedule_interval, catchup=False)
def report_zmey56_table():
@task()
def get_feed_action():
views_and_likes_per_user = """
SELECT
toDate(time) event_date,
user_id,
gender,
multiIf(age < 18, '<18',
age >= 18 and age < 20, '18-19',
age >= 20 and age < 30, '20-29',
age >= 30 and age < 40, '30-39',
age >= 40 and age < 50, '40-49',
age >= 50 and age < 50, '50-49',
'>60') age,
os,
countIf(action, action='like') likes,
countIf(action, action='view') views
FROM
simulator_20220620.feed_actions
where toDate(time) = yesterday()
group by event_date,user_id,gender,age,os
"""
return ph.read_clickhouse(query=views_and_likes_per_user, connection=connection_ro)
@task()
def get_message_action():
recive_and_send_message_per_user = """
with send as(
select
toDate(time) event_date,
user_id,
gender,
multiIf(age < 18, '<18',
age >= 18 and age < 20, '18-19',
age >= 20 and age < 30, '20-29',
age >= 30 and age < 40, '30-39',
age >= 40 and age < 50, '40-49',
age >= 50 and age < 50, '50-49',
'>60') age,
os,
count(*) messages_sent,
uniqExact(reciever_id) users_sent
FROM
simulator_20220620.message_actions
where toDate(time) = yesterday()
group by event_date,user_id,gender,age,os),
recieve as(
select
toDate(time) event_date,
reciever_id,
count(*) messages_received,
uniqExact(user_id) users_received
FROM
simulator_20220620.message_actions
where toDate(time) = yesterday()
group by event_date, reciever_id)
select
event_date,
user_id,
gender,
age,
os,
messages_sent,
users_sent,
messages_received,
users_received
from send
left join recieve on send.user_id = recieve.reciever_id
"""
return ph.read_clickhouse(query=recive_and_send_message_per_user, connection=connection_ro)
@task()
def merge(df_1, df_2):
return df_1.merge(df_2, how='outer').fillna(0)
@task()
def age_group(df):
return (df.groupby(['event_date','age'])
.agg({'messages_sent': sum,
'users_sent': sum,
'messages_received': sum,
'users_received': sum,
'likes': sum,
'views': sum,
}).reset_index()
.assign(metric = 'age')
.rename(columns={'age':'metric_value'}))
@task()
def gender_group(df):
return (df.groupby(['event_date','gender'])
.agg({'messages_sent': sum,
'users_sent': sum,
'messages_received': sum,
'users_received': sum,
'likes': sum,
'views': sum,
}).reset_index()
.assign(metric = 'gender')
.rename(columns={'gender':'metric_value'}))
@task()
def os_group(df):
return (df.groupby(['event_date','os'])
.agg({'messages_sent': sum,
'users_sent': sum,
'messages_received': sum,
'users_received': sum,
'likes': sum,
'views': sum,
}).reset_index()
.assign(metric = 'os')
.rename(columns={'os':'metric_value'}))
@task()
def concat(df_1, df_2, df_3):
return pd.concat([df_1,df_2,df_3]).astype({'metric_value':str,
'messages_sent': int,
'users_sent':int,
'messages_received':int,
'users_received':int,
'likes':int,
'views':int,
'metric': str
})[['event_date', 'metric', 'metric_value', 'views', 'likes','messages_received', 'messages_sent', 'users_received', 'users_sent']]
@task()
def load_df_to_ch(df):
return ph.to_clickhouse(df, 'agladkikh8', index=False, connection=connection_rw)
feed_df = get_feed_action()
message_df=get_message_action()
app_df = merge(feed_df,message_df)
os_df = os_group(app_df)
gender_df = gender_group(app_df)
age_df = age_group(app_df)
full_df = concat(os_df,gender_df,age_df)
load_df_to_ch(full_df)
report_zmey56_table = report_zmey56_table()
That’s all for now. In the next article, we will continue to work with report automation.
Source images:
- https://airflow.apache.org
- https://www.researchgate.net
- https://www.educative.io
- https://en.wikipedia.org